
지금으로부터 7년 전, 국내뿐만 아니라 전 세계가 주목했던 세기의 대결이 있었습니다. 바로 프로 바둑기사 이세돌 9단과 AI 알파고의 대국인데요. 4승 1패로 알파고가 승리하며 대국은 막을 내렸습니다. 이세돌 9단이 승리할거라 예상하던 사람들은 큰 충격에 빠졌고, 이때만 해도 막연하기만 한 AI의 개념을 널리 알리는 계기가 되었습니다. 그렇다면 현재 AI는 어디까지 발전했을까요.
2022년 11월에 OpenAI가 ‘ChatGPT’를 출시하며 세계는 한 차례 더 충격에 휩싸였습니다. 바야흐로 생성형 AI의 데뷔인 셈입니다. 현재는 OpenAI의 ‘ChatGPT’를 선두로, 많은 기업들이 LLM모델을 이용하여 학습한 생성형 AI를 앞다투어 출시하고 있는 AI경쟁시대가 도래했습니다. 장안의 화제이지만, 아직은 생소한 개념인 생성형 AI와 LLM에 대해 알아 보겠습니다.

생성형AI와 LLM(대규모언어모델)
생성형(Generative) AI란 사전 학습된 모형(pre-trained model)의 인공신경망을 기반으로 이용자의 특정한 요구에 따라 능동적으로 새로운 결과를 생성해 내기 위해 훈련된 AI 시스템을 말합니다. 기존까지의 딥러닝 기반 AI기술이 단순히 기존 데이터를 기반으로 예측하거나 분류하는 정도였다면, 생성형 AI는 이용자가 요구한 질문이나 과제를 해결하기 위해 스스로 데이터를 찾아 학습하여 이를 토대로 능동적으로 데이터나 콘텐츠 등 결과물을 제시하는 한 단계 더 진화한 AI기술이라고 볼 수 있습니다.
그렇다면 생성형 AI의 핵심이 되는 LLM이란 무엇일까요. Large Language Model(LLM)은 직역하면, 아주 큰 언어 모델이란 뜻입니다. 자연어처리와 AI분야에서 쓰이는 매우 큰 규모의 언어모델을 LLM이라고 합니다. LLM은 수십억개 혹은 그 이상의 파라미터를 갖추고, 대량의 텍스트 데이터를 학습하기 때문에 언어를 이해하고 생성하며 번역하는 등의 다양한 자연어처리 업무를 수행할 수 있습니다.
다만 이렇게 다양한 업무를 수행함으로써 우리의 삶을 더욱 윤택하게 해주는 LLM에도 한계는 존재합니다. 바로 ‘할루시네이션’과 ‘데이터 편향’에 따른 오류를 범할 가능성입니다.
‘할루시네이션(Hallucination)’은 환각, 환영이라는 뜻으로, 정보를 처리하는 과정에서 발생하는 오류를 말합니다. 맥락에서 벗어났거나 잘못된 정보를 마치 정답처럼 생성하는 현상을 일컫습니다. 또한 LLM은 다량의 데이터를 수집하여 학습하기 때문에 의도치 않게 편향된 정보와 차별적인 정보들을 학습하여 답할 수 있습니다.
이 경우, 올바르지 않은 결과물을 생성할 수 있기 때문에 이용자는 결과값에 대해 맹목적인 신뢰는 지양해야 하고, 원천이 되는 데이터 혹은 사실여부에 대해 검증하고 판단할 필요가 있습니다.
LLM 기반의 생성형AI를 현명하게 이용하는 방법
LLM을 기반으로 한 생성형 AI를 이용하는 방법은 일반적으로 Fine-tunning과 In-Context Learning이 있습니다.
Fine-tunning은 LLM이 특정한 작업을 더 잘 수행할 수 있도록 조금씩 미세하게 조정하는 것을 말합니다. LLM이 이미 데이터를 통해 기본적인 언어에 대한 포괄적인 사전학습이 되어있는 상태라고 가정했을 때, 특정한 데이터를 가지고 추가로 훈련시켜 원하는 의도의 특정작업을 더 잘 수행하게 하는 것입니다. 그런데 이러한 작업은 결국 추가 데이터를 가지고 LLM을 재훈련시키는 것이기 때문에 소요되는 시간이 점점 늘어나고 비용이 많이 듭니다.
따라서 별도의 재훈련 없이 명령 프롬프트만으로 수행시키는 방안이 있습니다. 이를 In-Context Learning이라고 합니다. In-Context Learning은 정보값 예시를 어떻게 주느냐에 따라 few-shot, one-shot, zero-shot으로 나누어집니다.
생성형 AI에 ‘복숭아는 종류가 뭐야?’라고 질문하면, LLM모델은 학습된 데이터를 기반으로 텍스트에 이어질 말을 예측하여 답변할 것입니다. 원하는 답은 ‘복숭아는 과일입니다’이지만, 확률에 따라 다른 답변을 할 수도 있습니다. 실제로 ‘복숭아는 종류가 뭐야?’는 사용자 입장에서는 질문이지만, LLM모델에겐 단순한 정보값이기 때문입니다.

-zero-shot-
위 사진은 LLM중 GPT-3를 기반으로 만들어진 챗봇 서비스인 ChatGPT입니다.
‘복숭아는 종류가 뭐야?’라고 물어보니 복숭아의 품종을 나열하여 답변한 것을 확인할 수 있었습니다. 이와 같이 예시 없이 바로 명령하는 것을 zero-shot이라고 합니다.
그렇다면 one-shot은 뭘까요. 이름에서 유추할 수 있듯이, 한 개의 예시를 함께 주는 것 입니다.
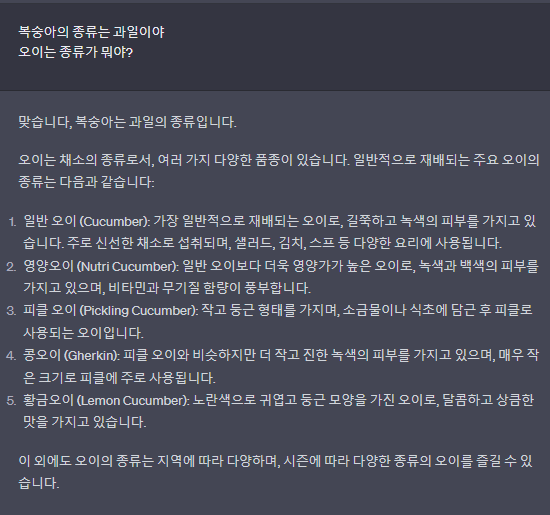
-one-shot-
복숭아는 과일이라는 한 개의 예시를 주고 오이의 종류가 뭔 지 질문하니 오이의 종류를 말해주는 것을 확인할 수 있었습니다.

-few-shot-
이번에는 여러 개의 예시와 함께 질문해 보았습니다. 예시를 파악하여 원하는 정보값만 주는 걸 확인할 수 있었습니다. 여러 개의 예시를 통해 가이드를 준다면 더 좋은 답변을 생성해냅니다.
이처럼 예시를 주는 것 외에도 ‘너는 사용자가 질문하는 게 과일인지 채소인지 분류하는 챗봇이야. 품종에 대한 설명은 하지 않아.’ 등의 프롬프트 입력을 통해 LLM모델이 원하는 답변을 생성할 수 있도록 명령할 수 있습니다. 이렇게 가이드를 주며 명령하는 것을 프롬프트 엔지니어링이라고 하며, 이런 방법들을 적절하게 섞어서 이용함으로써 LLM을 현명하게 사용할 수 있습니다.
LLM을 활용한 생성형AI 서비스
현재 다양한 기업들이 자체적인 LLM을 만들고, 그를 통해 학습시킨 다양한 생성형 AI서비스를 제공하고 있습니다.
먼저 생성형 AI의 시대를 연 OPEN AI의 챗지피티(Chat GPT)입니다. 2021년 9월까지 인터넷, 서적, 기사 및 기타 출처의 방대한 텍스트 데이터 학습했으며, 많은 사람들에게 생성형 AI를 알리는 계기가 되었습니다.
다음으로는 네이버의 HyperCLOVA(하이퍼클로바)입니다. 네이버의 Hyper CLOVA는 한국어로 특화한 생성형AI입니다. GPT-3보다 6500배 이상의 한국어 데이터 보유중인 것으로 알려져 있습니다. 현재 기업고객을 대상으로 NO-CODE AI도구인 CLOVA Studio를 제공하고 있습니다. 국내에서의 생성형 AI를 통한 서비스를 제공할 때 HyperCLOVA를 이용할 경우, 한국어에 대한 질의-답변의 정확성과 성능 높은 결과를 낼 수 있다는 장점이 있습니다.
세번째는 카카오의 KoGPT와 minDALL-E(민달리)입니다. 해당 모델은 GPT-3모델을 기반으로 합니다. KoGPT의 경우, 한국어를 사전적, 문맥적으로 이해하고 사용자의 의도에 맞춘 문장을 생성할 수 있습니다. minDALL-E는 텍스트로 명령어 입력 시, 요청에 따라 실시간으로 이미지를 생성할 수 있습니다.
네번째는 LG의 엑사원(EXAONE)입니다. 3000억개의 파라미터, 6000억개의 말뭉치, 2억 5000만개의 이미지를 학습한 모델로, 인간을 위한 전문적인 모델임을 피력하고 있습니다. 언어, 이미지, 영상에 이르기까지 인간의 의사소통에 관련한 다양한 정보를 습득하고 활용이 가능한 멀티 모달리티 능력을 보유하고 있습니다.
다섯번째로 허깅페이스(Hugging face)입니다. 허깅페이스는 ‘기계학습을 위한 깃허브(GitHub)’를 모토로 만들어진 커뮤니티며, 트랜스포머를 기반으로 하는 여러가지 모델들과 학습 스크립트를 다양한 방법으로 사용하고 공유할 수 있습니다.
마지막으로 메타의 라마(LLaMa)가 있습니다. ‘라마’는 매개변수가 70억개에서 650억개 사이로 기존 LLM보다 작지만 성능은 뛰어납니다. 현재 메타는 라마를 오픈소스로 공개하고 있습니다.